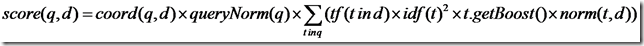影响Lucene对文档打分的四种方式
在索引阶段设置Document Boost和Field Boost,存储在(.nrm)文件中。
如果希望某些文档和某些域比其他的域更重要,如果此文档和此域包含所要查询的词则应该得分较高,则可以在索引阶段设定文档的boost和域的boost值。
这些值是在索引阶段就写入索引文件的,存储在标准化因子(.nrm)文件中,一旦设定,除非删除此文档,否则无法改变。
如果不进行设定,则Document Boost和Field Boost默认为1。
Document Boost及FieldBoost的设定方式如下:
|
|
两者是如何影响Lucene的文档打分的呢?
让我们首先来看一下Lucene的文档打分的公式:
score(q,d) = coord(q,d) · queryNorm(q) · ∑( tf(t in d) · idf(t)2 · t.getBoost() · norm(t,d) )
Document Boost和Field Boost影响的是norm(t, d),其公式如下:
norm(t,d) = doc.getBoost() · lengthNorm(field) · ∏f.getBoost()
field f in d named as t
它包括三个参数:
- Document boost:此值越大,说明此文档越重要。
- Field boost:此域越大,说明此域越重要。
- lengthNorm(field) = (1.0 / Math.sqrt(numTerms)):一个域中包含的Term总数越多,也即文档越长,此值越小,文档越短,此值越大。