
Akka in JAVA(二)
继续Akka in JAVA(一)中所讲.
Actor调用
从上面的例子中,我们可以大概的对AKKA在JAVA中的使用有一个全局的概念.这里我们在稍微细致的讲解一下.
在JAVA中使用AKKA进行开发主要有这几个步骤:
- 定义消息模型.
- 创建Actor的实现,以及业务逻辑
- 在需要使用AKKA的地方获取到ActorSystem,然后根据业务的数据流,获取到合适的Actor,给Actor发送消息.
- 在Actor的实现用,对接收到的消息进行具体的处理或转发.从而形成业务逻辑流.
下面我们分别讲解一下这几个步骤.
定义消息模型
在AKKA中的消息模型可以是任意实现了Serializable接口的对象.和大多数的远程调用框架一样,为了AKKA的高可用,以后可能会牵涉到远程调用和集群,那么消息模型就需要跨网络的进行传输,这就要求对消息模型进行序列化和反序列化.因此,要求消息模型必须实现Serializable接口.具体的序列化和反序列化在后面讲解远程调用的时候再细谈.
创建Actor的实现.
有了消息模型后,就需要有Actor对这些消息进行消费了.
在AKKA中Actor分为了TypedActor和UnTypedActor.
其中TypedActor是Akka基于Active对象(Active Object)设计模式的一个实现,该设计模式解耦了在一个对象上执行方法和调用方法的逻辑,执行方法和调用方法分别在各自的线程上独立运行.该模式的目标是通过使用异步的方法调用和内部的调度器来处理请求,从而实现方法的执行时异步处理的.通俗点来讲,TypedActor就是可以预先的定义一系列的接口和实现,然后通过ActorSystem来创建这个TypedActor的实例,当调用这个实例的方法的时候,其实是会异步的执行方法的,而不是同步的.至于如何异步的,这就交由AKKA内部来实现了,开发人员不需要关心.这其实就比较像goLang语言中的fmt的一些方法或go关键字,很简单的方法调用背后隐藏了异步的执行操作.
而UnTypedActor更像是JAVA中的JMS调用.方法的调用和执行完全依赖了消息,通过消息的类型或内容来区别不同的执行.对于消息的发送方式都是相同的,那就是直接给这个Actor的邮箱中发送Message.也就是说UnTypedActor更接近于我们前两个小节中所说的Actor这个概念.
事实也是如此,在AKKA中我们更多的是倾向于使用UnTypedActor向Actor系统间传递消息,而TypedActor更多的是用来桥接Actor系统和非Actor的.
创建UnTypedActor
在AKKA for JAVA中,创建一个UnTypedActor非常的简单.直接继承UnTypedActor类,并实现public void onReceive(Object message) throws Exception方法即可.在onReceive方法中就是需要实现的业务逻辑.比如:
|
|
创建TypedActor
由于AKKA是由scala写的,因此它其实最切合的就是使用scala进行开发,而JAVA作为一个强类型的静态语言,很多scala的特性其实是不好模仿出来的.因此,在JAVA中使用TypedActor其实是比较麻烦的.
首先需要定义
Actor的接口.对于异步的方法,需要返回scala.concurrent.Future对象.阻塞的异步调用,需要返回akka.japi.Option.同步调用直接返回结果对象.比如:12345678public interface Squarer {Future<Integer> square(int i); //non-blocking send-request-replyOption<Integer> squareNowPlease(int i);//blocking send-request-replyint squareNow(int i); //blocking send-request-reply}写
TypedActor的实现:123456789101112131415161718192021222324252627282930public class SquarerImpl implements Squarer {private String name;public SquarerImpl() {this.name = "default";}public SquarerImpl(String name) {this.name = name;}public Future<Integer> square(int i) {return Futures.successful(squareNow(i));}public Option<Integer> squareNowPlease(int i) {return Option.some(squareNow(i));}public int squareNow(int i) {try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("执行里面");return i * i;}}在调用AKKA的地方实例化
TypedActor的实例:1234567891011121314final ActorSystem system = ActorSystem.create("helloakka");/*默认构造方法的Actor*/Squarer mySquarer = TypedActor.get(system).typedActorOf(new TypedProps<>(Squarer.class, SquarerImpl.class));/*传参构造的Actor*/Squarer otherSquarer =TypedActor.get(system).typedActorOf(new TypedProps<>(Squarer.class,new Creator<SquarerImpl>() {public SquarerImpl create() {return new SquarerImpl("foo");}}),"name");执行
TypedActor中的方法:123456789Option<Integer> oSquare = mySquarer.squareNowPlease(10); //Option[Int]System.out.println("阻塞异步调用执行外面");//获取结果System.out.println(oSquare.get());Future<Integer> fSquare = mySquarer.square(10); //A Future[Int]System.out.println("非阻塞异步执行外面");//等待5秒内返回结果System.out.println(Await.result(fSquare, Duration.apply(5, TimeUnit.SECONDS)));执行后会在控制台打印:
123456执行里面阻塞异步调用执行外面100非阻塞异步执行外面执行里面100
从这个结果很容易的看出成功的异步调用了Actor.
小结
从上面的例子可以看出TypedActor其实在JAVA中是比较麻烦的,因此我们会更多的使用UnTypedActor.后面的例子中Actor指的都是UnTypedActor
获取Actor
在创建了Actor后,接下来就是需要实例化或获取Actor了.其主要是通过ActorSystem中的actorOf和actorSelection以及actorFor三个方法.
- actorOf:创建一个新的Actor。创建的Actor为调用该方法时所属的Context下的直接子Actor;
- actorSelection:当消息传递来时,只查找现有的Actor,而不会创建新的Actor;在创建了selection时,也不会验证目标Actors是否存在;
- actorFor(已经被actorSelection所deprecated):只会查找现有的Actor,而不会创建新的Actor。
Actor生命周期
AKKA为Actor生命周期的每个阶段都提供了一个钩子(hook),我们可以在必要的时候重载这些方法来完成一些事情。如下图所示:
因此,基本上,一个Actor的生命周期依此为:
|
|
为了更好的理解Actor的生命周期,官方还出了一个图来进行描述: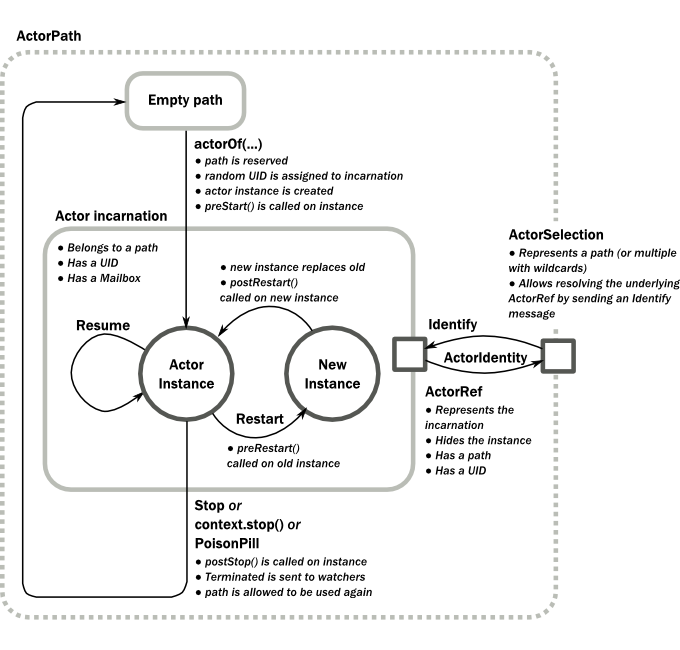
从上图我们可以看到,一个Actor初始的时候路径是空的,通过调用actorOf方法实例化一个Actor的实例,会返回一个ActorRef来表示Actor的引用.它包含了一个UID和一个Path,这两个值共同的标识了一个Actor的唯一.重启操作Path和UID不会改变,因此重启前获取到的ActorRef继续有效.
但是ActorRef的生命周期在actor停止的时候结束.此时适当的生命周期Hook会被调用, 处于监控状态的actor会收到通知.在该Actor结束后, 此路径可以通过actorOf方法重用.此时新的ActorRef的路径和之前一样但是UID不同.所以在停止前获取到的ActorRef不再有效.
与ActorRef不同,ActorSelection只关心Path而不关心具体是哪一个Actor.也就是说对一个明确路径的ActorSelection来说,无论对应的Actor是重启还是重新创建,只要是路径一样的,那么都是有效的.如果要通过ActorSelection来获取一个具体的Actor,需要调用ActorSelection的resolveOne的方法来获取.
Dispatcher
在AKKA中,actor之间都是通过消息的传递来完成彼此的交互的.而当Actor的数量比较多后,彼此之间的通信就需要协调,从而能更好的平衡整个系统的执行性能.
在AKKA中,负责协调Actor之间通信的就是Dispatcher.它在自己独立的线程上不断的进行协调,把来自各个Actor的消息分配到执行线程上.
在AKKA中提供了四种不同的Dispatcher,我们可以根据不同的情况选择不同的Dispatcher.
- Dispatcher:这个是AKKA默认的
Dispatcher.对于这种Dispatcher,每一个Actor都由自己的MailBox支持,它可以被多个Actor所共享.而Dispatcher则由ThreadPool和ForkJoinPool支持.比较适合于非阻塞的情况. - PinnedDispatcher:这种Dispatcher为每一个Actor都单独提供了专有的线程,这意味着该Dispatcher不能再Actor之间共享.因此,这种Dispatcher比较适合处理对外部资源的操作或者是耗时比较长的Actor.PinnedDispatcher在内部使用了ThreaddPool和Executor,并针对阻塞操作进行了优化.所以这个Dispatcher比较适合阻塞的情况.但是在使用这个Dispatcher的时候需要考虑到线程资源的问题,不能启动的太多.
- BalancingDispatcher(已被废弃):它是基于事件的Dispatcher,它可以针对相同类型的Actor的任务进行协调,若某个Actor上的任务较为繁忙,就可以将它的工作分发给闲置的Actor,前提是这些Actor都属于相同的类型.对于这种Dispatcher,所有Actor只有唯一的一个MailBox,被所有相同类型的Actor所共享.
- CallingThreadDispatcher:这种Dispatcher主要用于测试,它会将任务执行在当前的线程上,不会启动新的线程,也不提供执行顺序的保证.如果调用没有及时的执行,那么任务就会放入ThreadLocal的队列中,等待前面的调用任务结束后再执行.对于这个Dispatcher,每一个Actor都有自己的MailBox,它可以被多个Actor共享.
如果要配置Dispatcher,可以在项目的resource目录中创建一个conf文件(默认名字为application.conf).然后修改其中的配置:
|
|
其中writer-dispatcher是dispatcher的名字,同一个配置文件中可以配置多个.type为四种类型中的某一个.executor是底层实现方式,通常有两种fork-join-executor和thread-pool-executor.这两种的参数为:
- core-pool-size-min/parallelism-min : 最小线程数
- core-pool-size-max/parallelism-max : 最大线程数
- core-pool-size-factor/parallelism-factor: 线程层级因子,通常和CPU核数相关.
要在AKKA中使用配置文件,需要在创建ActorSystem的时候进行指定:
|
|
ConfigFactory.load("demo5")读取的就是Resource文件夹中的demo5.conf这个配置文件.getConfig("demo5")读取的是这个配置文件中的demo5这部分的配置.
而要使用配置的Dispatcher需要在创建Actor实例的时候,使用withDispatcher(String)方法来指定:
|
|
这里有一个简单的例子,就是发送消息给一堆的Actor,每一个Actor接收到消息后打印出线程的名字:
StartCommand.java
|
|
WriterActor.java
|
|
ControlActor.java
|
|
AkkaMain5.java
|
|
执行这个程序,执行的结果为:
|
|
可以看出线程被重复的利用了.仔细数的话,一共只有10个线程.
而如果把Dispatcher的类型改成PinnedDispatcher的话,系统就会创建100个线程出来.符合开始说的区别.
Router
在真实的情况中,通常针对某一种消息,会启动很多个相同的Actor来进行处理.当然,你可以在程序中循环的启动很多个相同的Actor来实现,就如上一小结中启动100个Actor那样,但是这就牵涉到Actor任务的平衡,Actor个数的维护等等,比较的麻烦.因此,在AKKA中存在一种特殊的Actor,即Router.Akka通过Router机制,来有效的分配消息给actor来完成工作.而在AKKA中,被Router管理的actor被称作Routee.
根据项目的需求,可以使用不同的路由策略来分发一个消息到actor中.Akka附带了几个常用的路由策略,配置起就可以使用.当然,也可以自定义一个路由器.
使用Router
要使用Router非常的简单,可以在Actor内通过实例化Router对象的方式来使用,也可以在Actor外通过withRouter的方式直接创建一个RouterActor来使用.
Actor内使用
这种方式是通过AKKA提供的API,手动的创建Router对象,然后调用addRoutee方法手动的添加Actor(需要注意,每一次调用addRoutee都会返回一个新的Router对象),然后通过route来发送消息.
|
|
这段代码首先创建了100个相同类型的Actor,然后实例化了一个Router,路由策略是轮询.然后把这100个Actor显式的加入到Router中. 最后,发送消息的时候通过router.route的方式进行发送.AKKA会把这个消息按照路由策略分发给某一个Actor中执行.
Actor外使用
这种方式是通过创建一个RouteActor来使用路由.RouteActor和一般的Actor没有什么不同,区别在于它没有什么业务逻辑,在创建它的时候,它会创建N个具备业务逻辑的子Actor.当它接收到消息后,会把消息转发给它的某个子Actor.
|
|
这段代码确定了子Actor的类型,然后定义了路由策略.而后创建了RouteActor.最后发送消息的时候通过给路由Actor发送消息的方式进行处理.
配置使用
这种方式是通过在AKKA的配置中来定义Router,创建的时候直接读取配置来获取Router.
|
|
这个就是在配置中指定了一个router,策略是轮询,子Actor数是5个.
|
|
然后通过FromConfig()配置加载Router.加载的时候需要指定router的名字.这个名字需要和配置中的Router的路径相对应.
内置Router
AKKA中一共内置了8种路由策略,他们分别是:
RoundRobinPool: 这个是最常用的,轮询方式分发消息
123456akka.actor.deployment {/parent/router1 {router = round-robin-poolnr-of-instances = 5}}RandomPool: 这个是随机方式分发消息
123456akka.actor.deployment {/parent/router5 {router = random-poolnr-of-instances = 5}}BalancingPool: 均衡分发消息,所有的子Routee共享一个邮箱,它会尝试重新从繁忙routee分配任务到空闲routee
123456akka.actor.deployment {/parent/router9 {router = balancing-poolnr-of-instances = 5}}SmallestMailboxPool: 最少消息邮箱分发,这个按照
- 选择有空邮箱的空闲Routee处理
- 选择任意空邮箱的Routee
- 选择邮箱中有最少挂起消息的routee
选择任一远程routee,远程actor优先级最低,因为其邮箱大小未知
123456akka.actor.deployment {/parent/router11 {router = smallest-mailbox-poolnr-of-instances = 5}}
BroadcastPool:这个Router比较特殊,是广播消息,也就是一个消息会被他所有的子Actor接收到,而不仅仅是其中的某一个.
123456akka.actor.deployment {/parent/router13 {router = broadcast-poolnr-of-instances = 5}}ScatterGatherFirstCompletedPool:这个Router也比较特殊,它会把消息发送到它所有的子Routee中,然后它会等待直到接收到第一个答复,该结果将发送回原始发送者.而其他的答复将会被丢弃.
1234567akka.actor.deployment {/parent/router17 {router = scatter-gather-poolnr-of-instances = 5within = 10 seconds}}TailChoppingPool:这个Router将首先发送消息到一个随机挑取的routee,短暂的延迟后发给第二个routee(从剩余的routee中随机挑选),以此类推.它等待第一个答复,并将它转回给原始发送者.其他答复将被丢弃.这样设计的目的在于使用冗余来加快分布式情况下的查询等业务.
12345678akka.actor.deployment {/parent/router21 {router = tail-chopping-poolnr-of-instances = 5within = 10 secondstail-chopping-router.interval = 20 milliseconds}}ConsistentHashingPool:使用一致性hash的方式来分发消息.它会把传送的消息映射到它的消息环上,然后进行Actor的选择.
1234567akka.actor.deployment {/parent/router25 {router = consistent-hashing-poolnr-of-instances = 5virtual-nodes-factor = 10}}
动态改变Routee数量
上述的大多数Route除了在配置或实例化的时候指定固定数量的Routee外,还能配置一个resize的策略,指定最大最小的Routee的数量:
|
|
|
|
Scheduler
在实际使用AKKA中,可能会需要定时或重复的发送消息给某些Actor.要处理这类的问题,除了直接使用JAVA的API或Quartz显式的重复调用ActorRef.tell外,AKKA还提供了一个简单的Scheduler.
AKKA的Scheduler比较简单,是由ActorSystem提供的,可以简单的对Actor发送重复或定时任务.
比如:
|
|
这个例子中,实例化了一个Actor.然后调用system.scheduler()获取到Scheduler,然后调用scheduleOnce(延迟时间,目标Actor,消息,调度器,发送者)方法延迟5秒再发送消息给某个Actor.
此外,除了延迟发送消息,Akka的Scheduler还提供了定时重复发送消息,比如:
|
|
这个例子中,调用了Scheduler的schedule(第一次调用时间,间隔时间,目标Actor,消息,调度器,发送者)方法每一秒发送一个消息给Actor.
需要注意的是Scheduler的这两个方法都会返回一个Cancellable对象.通过这个对象,我们可以显式的调用cancellable.cancel();来取消重复任务.
其实,除了能重复的给Actor发送消息外,AKKA的scheduler由于可以接收Runnable接口,所以基本上可以做任何的事情.例如,在Spark中,AppClient中的ClientActor需要与Master这个Remote Actor通信,从而注册所有的Spark Master.由于注册过程中牵涉到远程通信,可能会因为网络原因导致通信错误,因此需要引入重试的机会.

