
ELK(ElasticSearch+Logstash+Kiabana)初实践
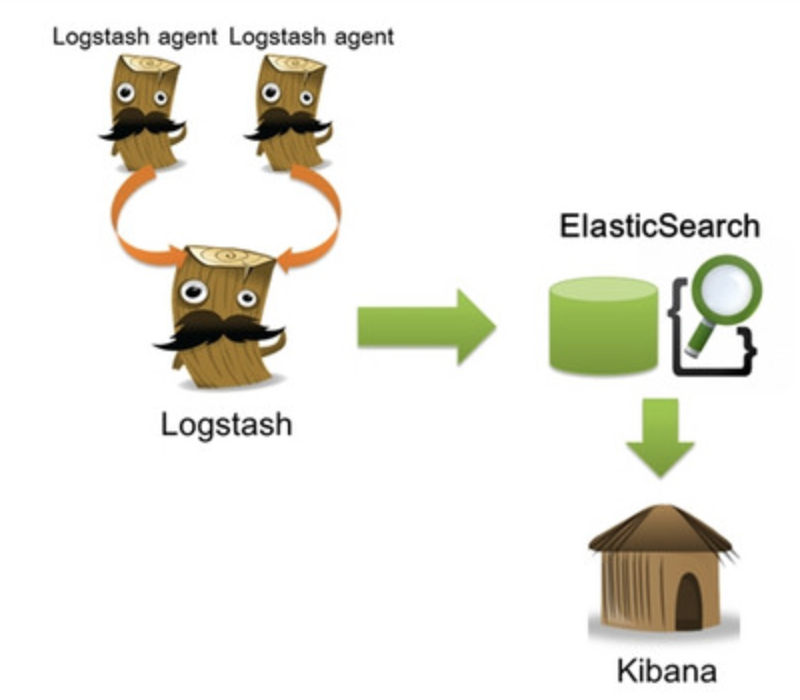
ELK是由elastic公司维护的开源的实时日志采集与分析三剑客.它能够在分布式的架构下,使用Logstash实时的采集各种不同来源的日志,并通过清洗/ETL转换,形成有意义的数据,存入到ElasticSearch全文检索引擎中,再通过Kiabana呈现出来.
我们可以通过这套开源系统实时的了解服务器的软硬件信息,业务负载,错误异常等等.同时也能统一收集日志并做归档处理.当管理的机器非常多的时候这就非常的有意义了.
ElasticSearch
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎.与Solr类似,它隐藏了Lucene的复杂性.并提供大量分布式的功能.使用者能够很简单的就构建起一个全文检索引擎,并提供出Restful的API.而不需要编写任何的代码.
安装
Elasticsearch的安装非常的简单,它只依赖JAVA的运行环境.最简的运行方式就是直接下载它编译好了的压缩包.然后解压即可用.
(默认JAVA运行环境已经配置完成)
- 从https://www.elastic.co/downloads/elasticsearch下载最新的运行包.
- 使用
tar -xvf elasticsearch-2.1.0.tar.gz解压 - 在
elasticsearch-2.1.0文件夹下执行./bin/elasticsearch 在浏览器中访问http://127.0.0.1:9200.如果得到一个JSON的结果,就表明ES启动成功
123456789101112{"name" : "Hood","cluster_name" : "elasticsearch","version" : {"number" : "2.1.0","build_hash" : "72cd1f1a3eee09505e036106146dc1949dc5dc87","build_timestamp" : "2015-11-18T22:40:03Z","build_snapshot" : false,"lucene_version" : "5.3.1"},"tagline" : "You Know, for Search"}如果你想要一个监控界面来控制和了解ES的话,可以下载marvel.
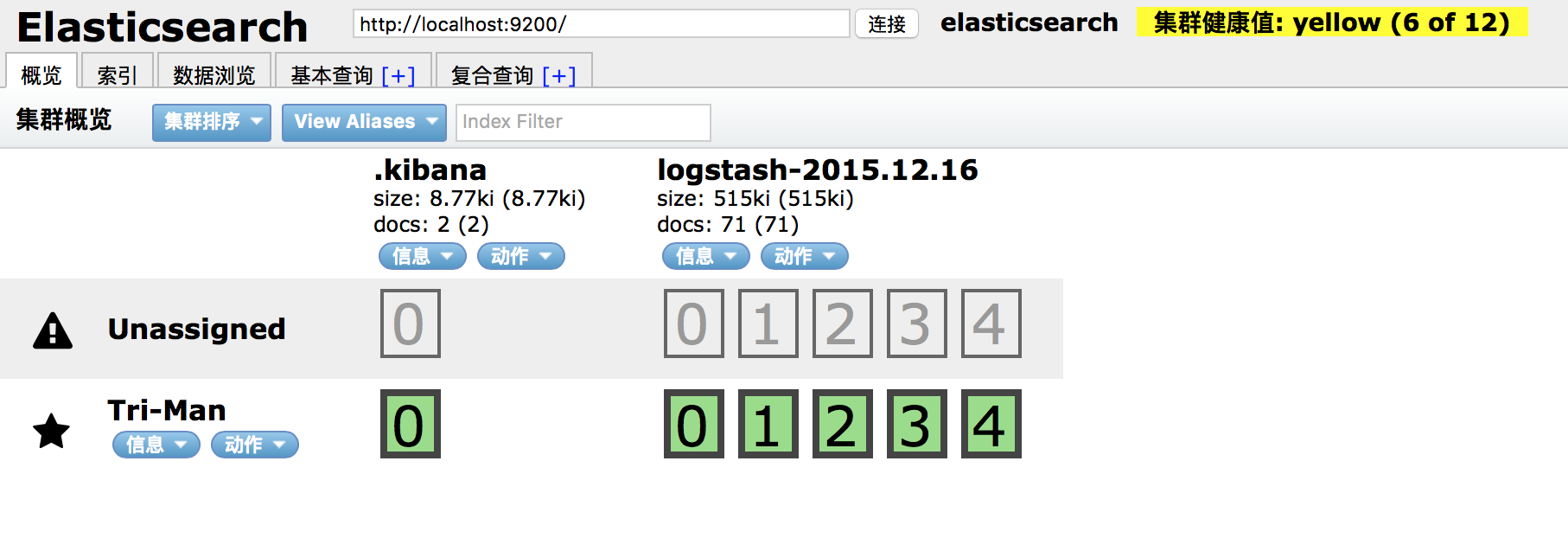
Marvel是Elasticsearch的管理和监控工具,在开发环境下免费使用.它包含了一个叫做Sense的交互式控制台,使用户方便的通过浏览器直接与Elasticsearch进行交互.不过这个东西不能进行商用.另外一个可视化的插件是Header,同样是一个ES的管理和监控的工具,不过它的功能稍微要少一些.- 安装
Header的话非常简单,直接在es的bin目录中执行sudo ./plugin install mobz/elasticsearch-head即可,它会自动的下载并解压安装包到plugins目录. 安装完成后,在浏览器中浏览http://localhost:9200/_plugin/head/
安装
Marvel稍微要麻烦一点,最新的Marvel2.X需要依赖Kiabana了.首先需要安装License模块:./plugin install license,然后在ES中安装marvel-agent:./plugin install marvel-agent,最后需要在Kiabana中安装marvel:./kibana plugin --install elasticsearch/marvel/latest安装完成后,启动
Elasticsearch和Kiabana.然后在浏览器中浏览http://localhost:5601/app/marvel即可.
剩下的Elasticsearch的其他使用,我会另开博文来讲述,这里主要是讲ELK的整合使用~
Kiabana
Kibana是一个基于浏览器页面的Elasticsearch前端展示工具,提供了非常牛逼的图表和表现能力。Kibana全部使用HTML语言和Javascript编写的.因此可以部署到任意的Web容器中去.当然,官网上下载的安装包中已经内置了一个Web容器,直接运行即可.
安装
- 从https://www.elastic.co/downloads/kibana下载最新的运行包.
- 使用
tar -xvf kibana-4.3.0-darwin-x64.tar.gz解压 修改
/config/kibana.yml文件,指定Elasticsearch的访问地址:12# The Elasticsearch instance to use for all your queries.elasticsearch.url: "http://localhost:9200"在
kibana-4.3.0-darwin-x64文件夹下执行./kibana即可. 他会自动的在ES中创建它自己所需的索引文件.在浏览器中打开http://127.0.0.1:5601/app/kibana即可.这个时候就可以在界面的
Discover中进行索引的查询了.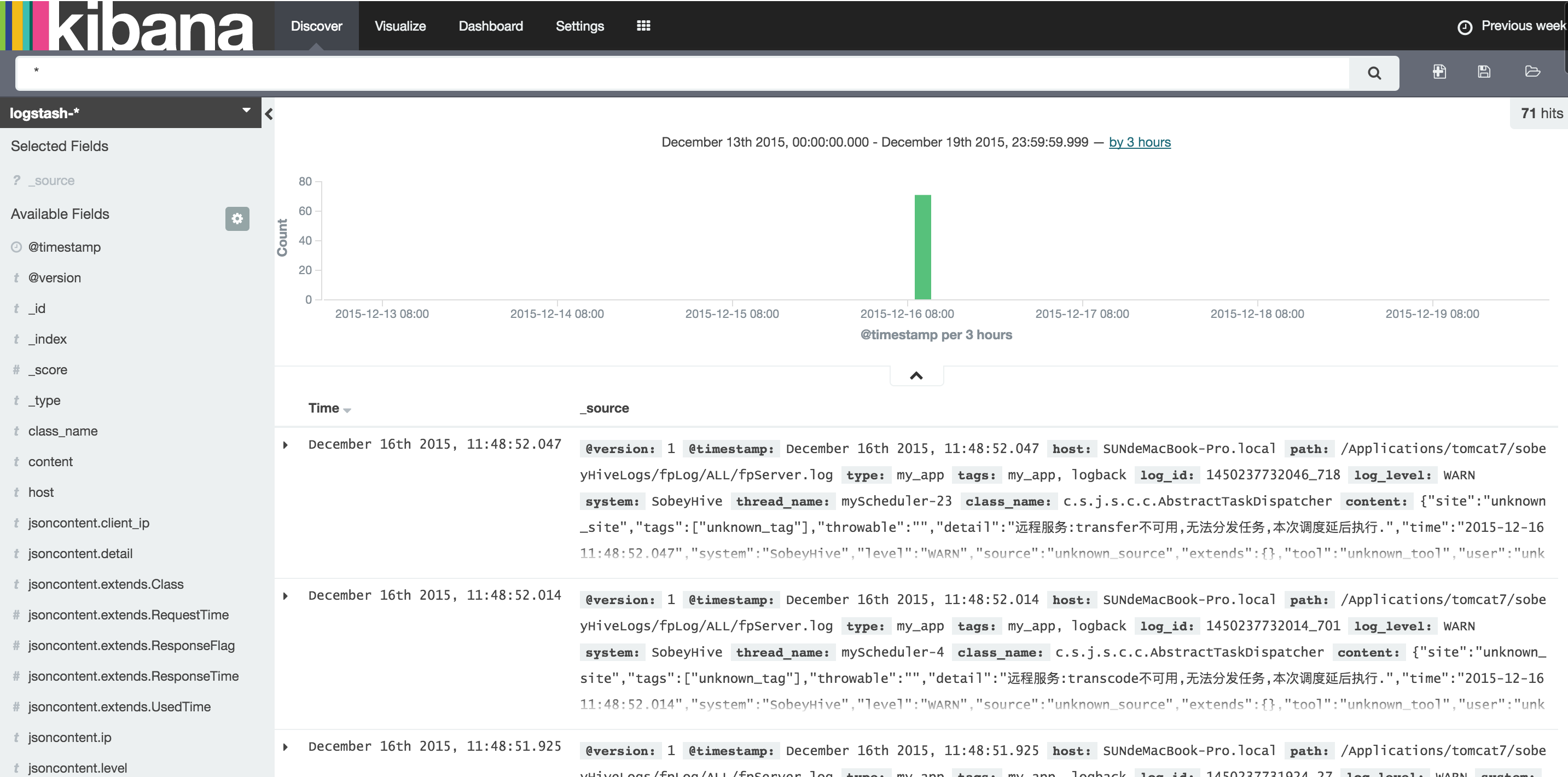
同时,也可以使用
Visualize功能,建立不同的报表.我们对日志的处理也主要就是通过记录的不同维度,建立不同的图表.然后订阅到Dashboard中.这样就能对日志进行实时的监控和分析.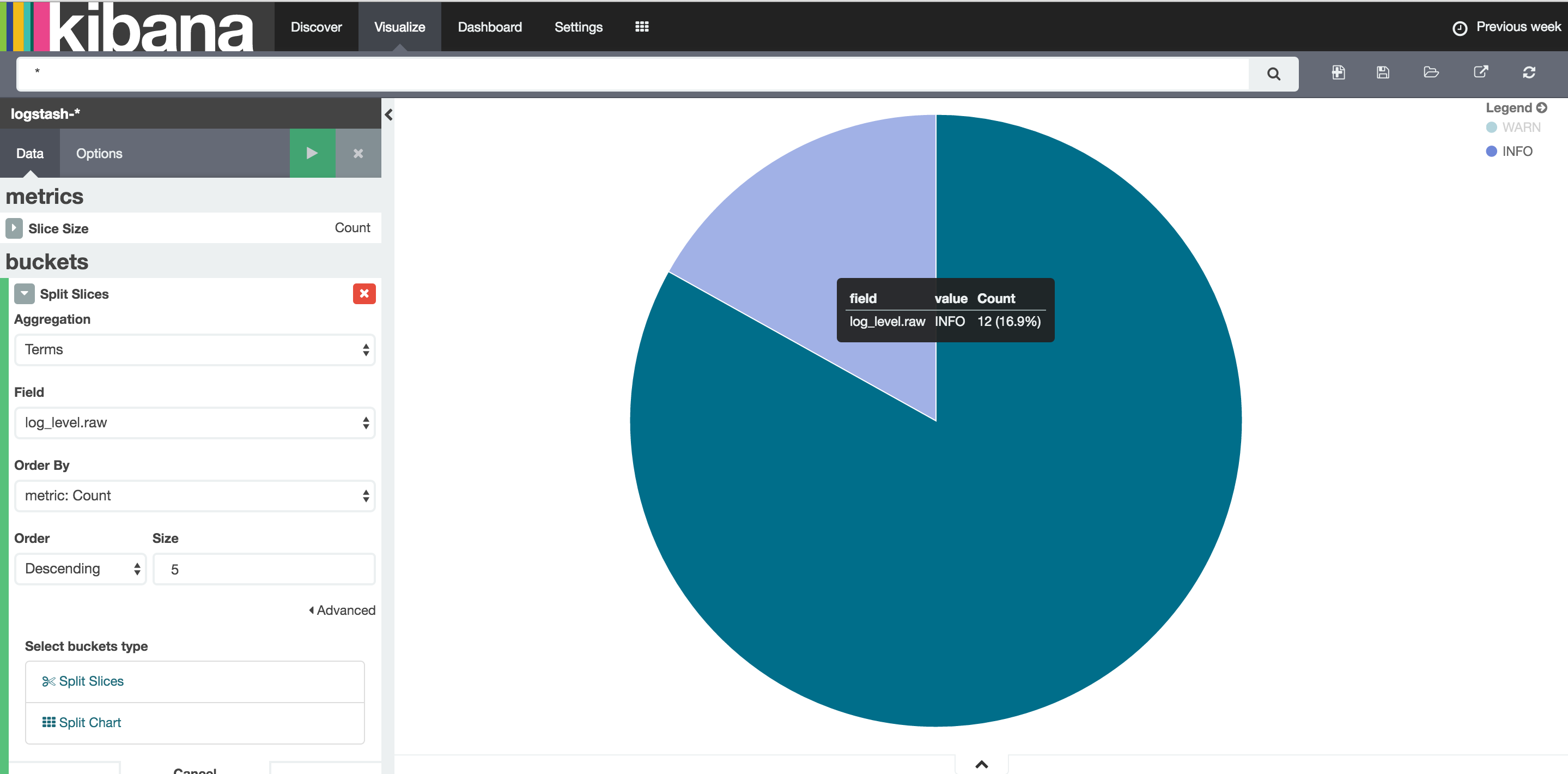
Logstash
Logstash是一个应用程序日志、事件的传输、处理、管理和搜索的平台.你可以用它来统一对应用程序日志进行收集管理.这点上它的功能其实和Flume是有点类似的.
安装
Logstash是使用JRuby写的,因此需要依赖JAVA的运行环境.
- 从https://www.elastic.co/downloads/logstash下载最新的运行包.
- 使用
tar -xvf logstash-2.1.0.tar.gz解压 - 在
logstash-2.1.0文件夹下执行./bin/logstash agent -f logstash.conf即可.
这里主要是使用了agent模式运行,采集日志的配置记录到logstash.conf文件中. 接下来就介绍一下logstash.conf这个文件.
配置
Logstash的日志采集过程主要有三个部分,分别是Input Filter和Output.对应了日志的收集,日志的整理和日志的输出,同时在Filter的前后允许配置Codec也就是编解码.每一个过程都提供了非常多的插件来辅助处理.具体有哪些插件可以访问Input,Filter,Output以及Codec.
比如最简单的一个conf文件为:
|
|
它指定了日志采集的输入源为命令行输入,不经过任何的处理,输出源为控制台输出,输出的时候编码为ruby的debug格式
执行这个采集的效果就是:
|
|
现在再来看一个复杂点的例子,这个是我们测试环境抓取业务日志的conf配置:
|
|
- 先来看看Input{}. 他使用了
file插件,从文件读取读取日志,并且给日志增加了一个Type属性用于区别来源.同时,1秒一次的监控日志的变化,把已扫描了的日志偏移量记录到./sincedb中去. - 接下来就是filter{}了.
- 一来,使用if语句,正则匹配
[]开头的日志行,这个符合这个正则的日志才予以保留,其他的日志直接删除掉. - 而后使用了grok插件,这个插件最重要的功能就是进行ETL转换,把非结构化的日志,转换成结构化的对象. 它使用正则表达式,以及
<xxxx>的形式用来匹配和挖取有用的变量. - 比如这个例子中的:
\[(?<log_id>.*?)\] (?<log_level>\w+) %{TIMESTAMP_ISO8601:log_time} (?<system>\w+) \[(?<thread_name>.+?)\] (?<class_name>.+)\- (?<content>.*)就是用来匹配[1450580425858_394] INFO 2015-12-20 11:00:25.873 XXXXXX [myScheduler-4] c.s.j.s.c.c.AbstractTaskDispatcher- {"site":"unknown_site","tags":["unknown_tag"],"throwable":"","detail":"扫描模式,fileanalysis组件调度器,开始恢复上次待分配的任务.isChangePriority=false","time":"2015-12-20 11:00:25.873","system":"XXXXXX","level":"INFO","source":"unknown_source","extends":{},"tool":"unknown_tool","user":"unknown_user","client_ip":"unknown_ip","ip":"172.16.129.7"}日志的. - 通过grok插件的处理,这个时候日志事件就变为一个结构化的数据了.针对这个数据我们就可以进行很多其他的处理.
- 下面使用了
date插件来处理日期.它定义了日期的标准格式,以及时区.然后把解析出来的时间赋值给模型上的某个字段. - 接下来,再次使用
if语句,对模型中的content字段再次进行清洗,对于不是JSON格式的日志,直接删除. - 最后,使用
json插件,把content字段JSON化.
最后使用output{}把转换好的日志输出到两个地方,一个是控制台,另外一个就是前文所说的elasticsearch了.
- 一来,使用if语句,正则匹配
当我们执行这个日志采集Agent后,他就会不断的监控日志文件.一旦日志文件有变化,他就会采集到,并做处理,然后发送到es中. 最后我们就可以使用kibana来进行查看了.
总结
本文主要介绍了ELK的作用,以及安装. 以一个简单的配置例子,介绍了ELK整合的常用方式以及效果.
通过ELK,可以把以前很麻烦的分布式日志的收集和整理简单化了.
更高级的功能,随着我使用的深入,会继续更新博文.

