
使用Lucene进行索引部分更新缓慢原因分析
问题的引出
在我们的系统中,使用了Lucene作为全文检索引擎用作NRT近实时检索.这就牵涉到一个更新的问题.
在Lucene当中,其实是不存在部分更新的说法的,它仅仅支持全更新.因此,为了应用端的调用方便.在我们的FTEngine全文检索引擎中是提供了部分更新的功能的,其逻辑大体上来说,就是根据传入的uniqueID,在索引中找到对应的Document.然后再恢复它的Term.而后再构造全更新的Document,交由Lucene进行全更新.
但是,在北京台项目中,突然发现全文检索更新的很慢,往往页面都对素材修改了2个小时了,索引都还没有更新. 从而引出了这个问题.
解决思路
经过最初步的分析, 发现发生这种现象多集中于有大量的归档与回迁的操作.这两个操作对索引的影响就是会一次性的大量的进行索引的部分更新. 因此就把原因怀疑到了部分更新上.
分析过程
- 修改FTEngine的源代码.在项目中,加入大量的日志,全部显示使用时间.
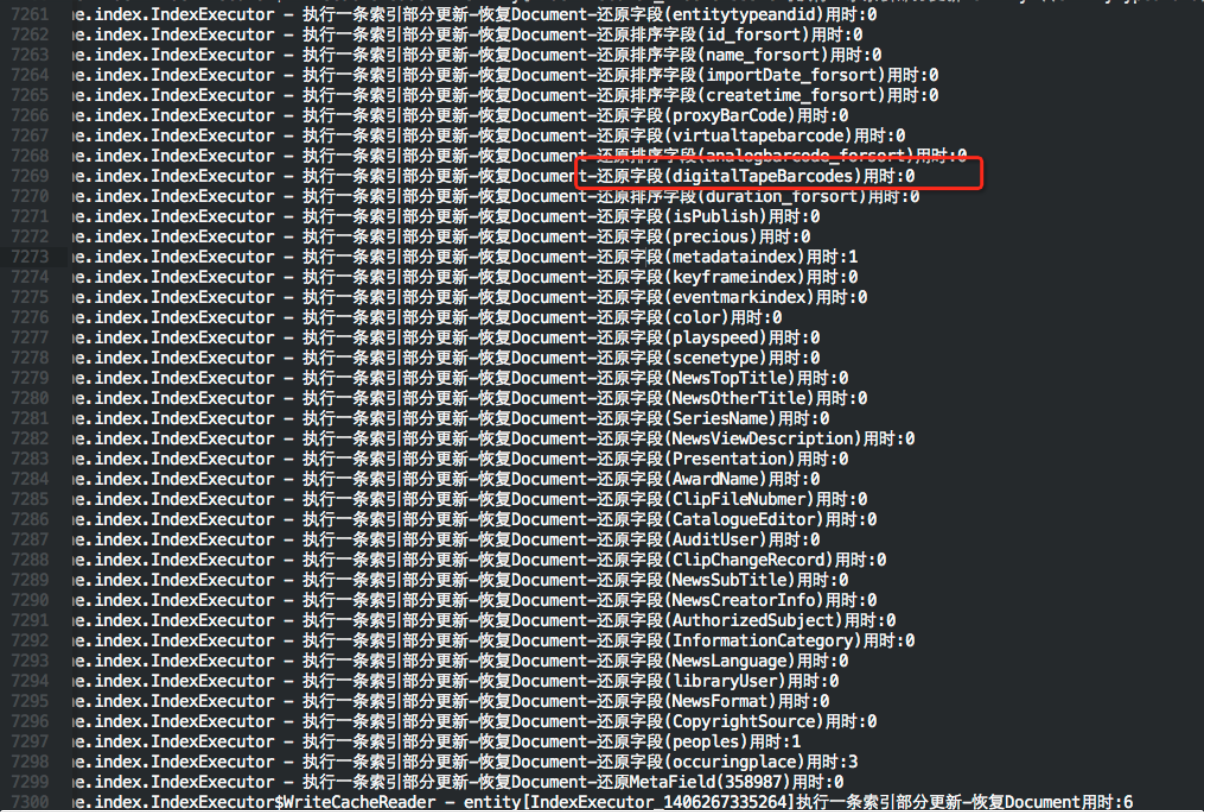
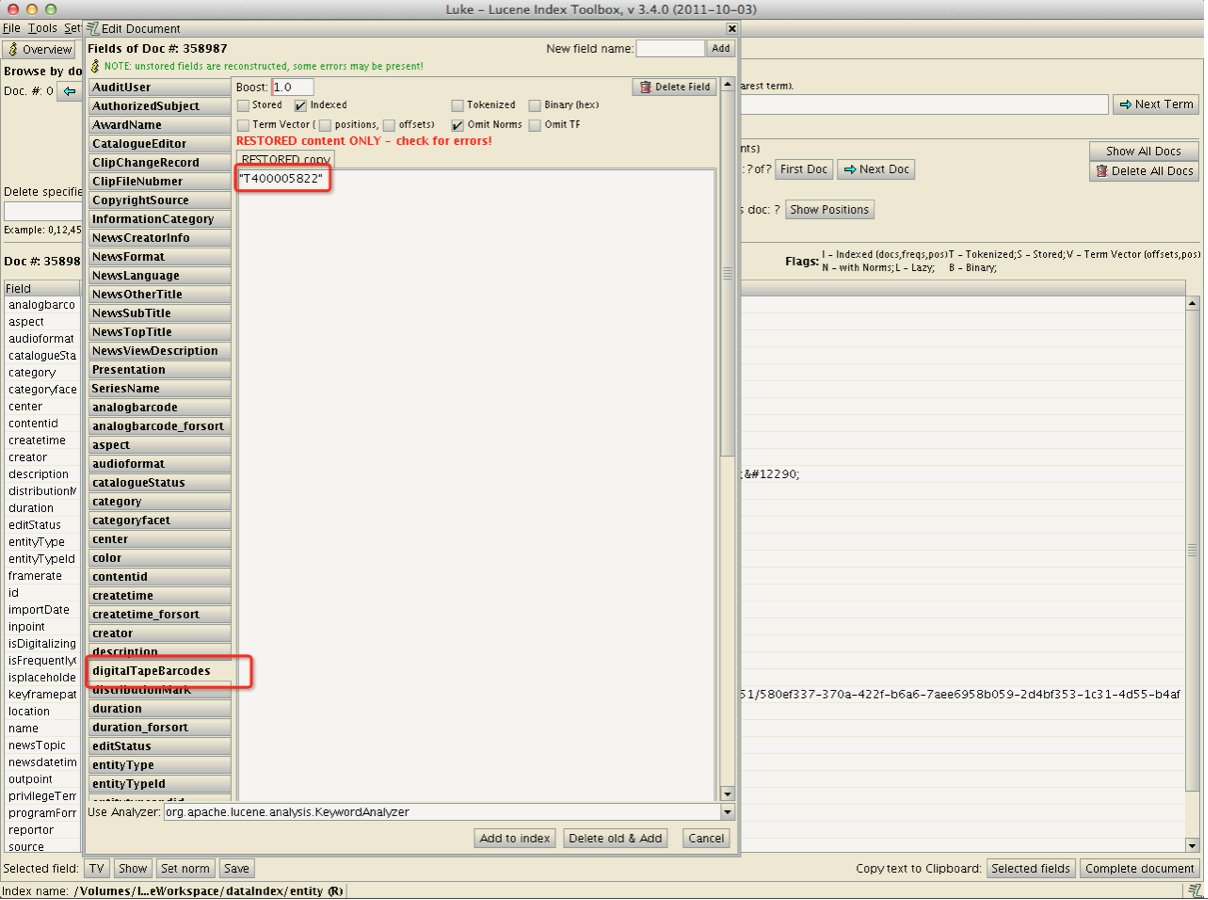
发现程序在恢复没有Store的字段的Term的时候非常的慢.经过分析以及网上找问题,发现是由于我们对于Index的字段没有使用Lucene提供的TermVector功能,也就是Term的位置向量.它是以空间来换取时间,当使用了位置向量后,就相当于为每一个Term都编了号,记录了位置.这样在恢复的时候大大的提高了查询Term的性能.这样就能很快的恢复Document了.
经过修改后,再进行测试,发现有些Document的恢复还是很慢. 对比恢复的快的与慢得Document.发现他们的区别在于恢复字段的时候,如果每一个字段都是有值的,那么由于有termVector那么会非常的快.但是如果这个字段是没有值的,那么恢复Term就相当的慢.
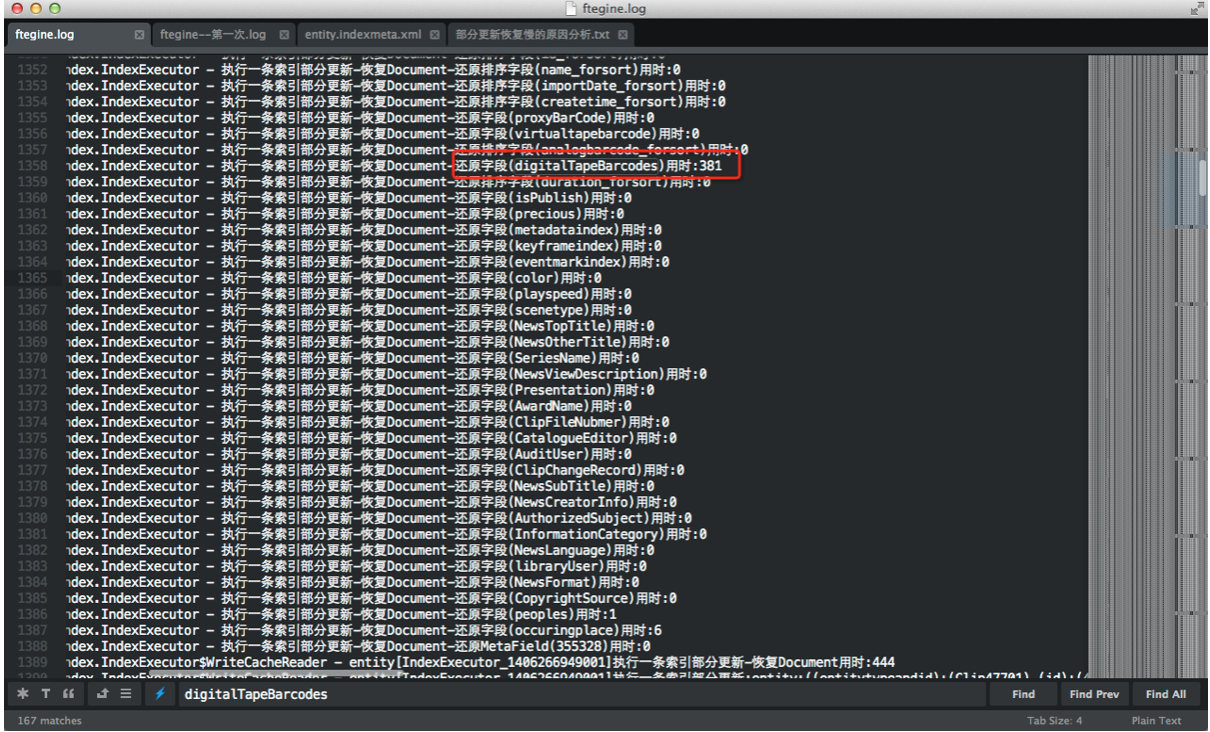
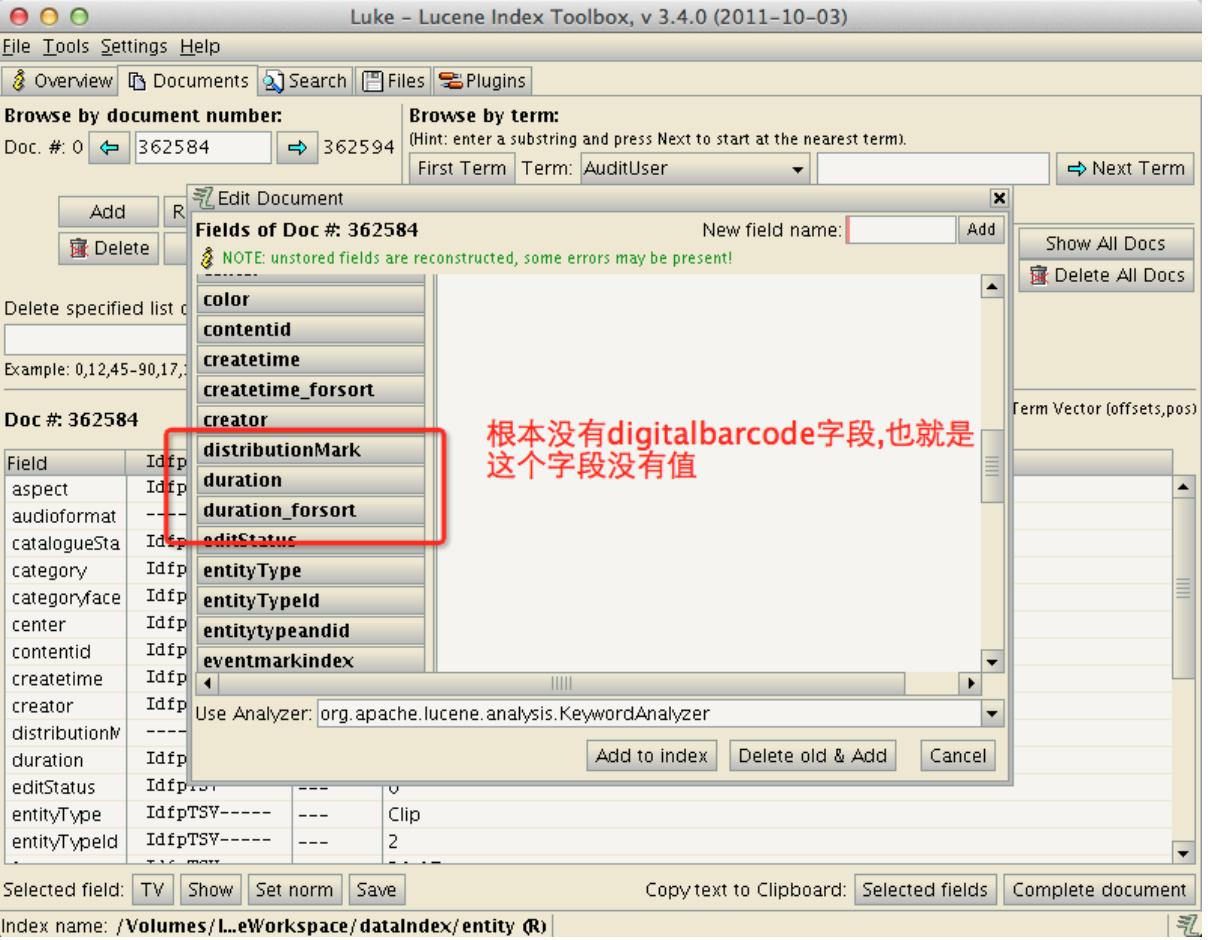
进一步分析,没有digitalbarcode字段,那么他恢复这个的时候是如何处理的呢?
代码先去找这条记录的这个字段是否有Vector向量.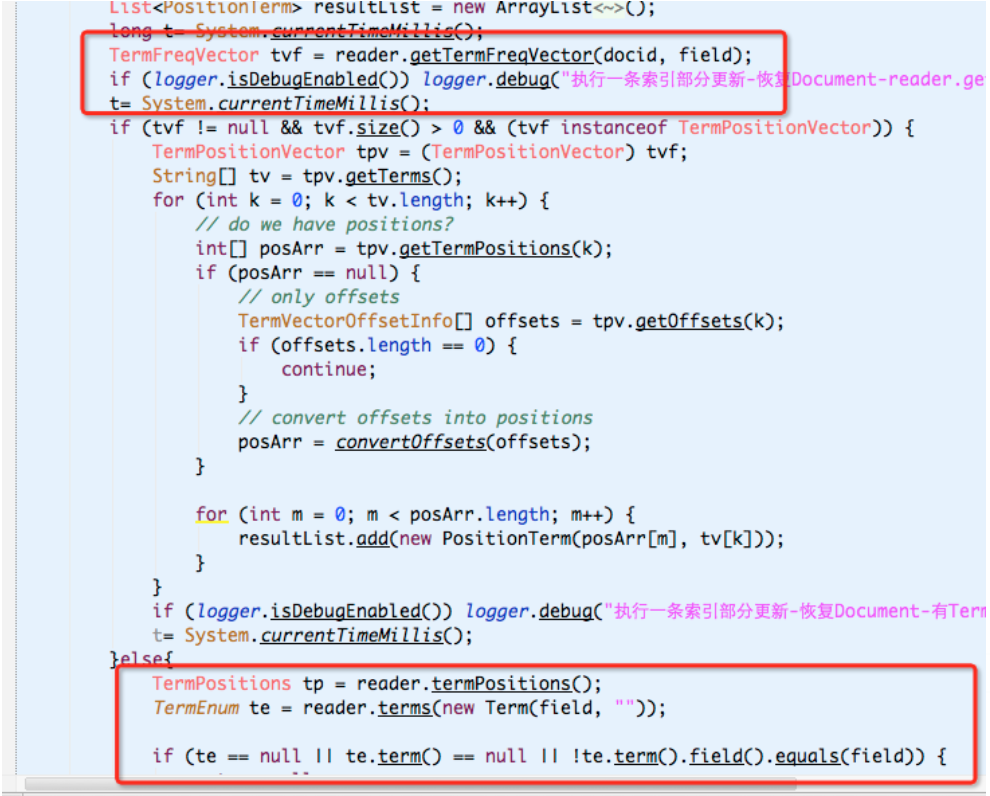
因为该条Documnet根本就没有这个字段,所以肯定没有这个向量.所以他走到else中去了.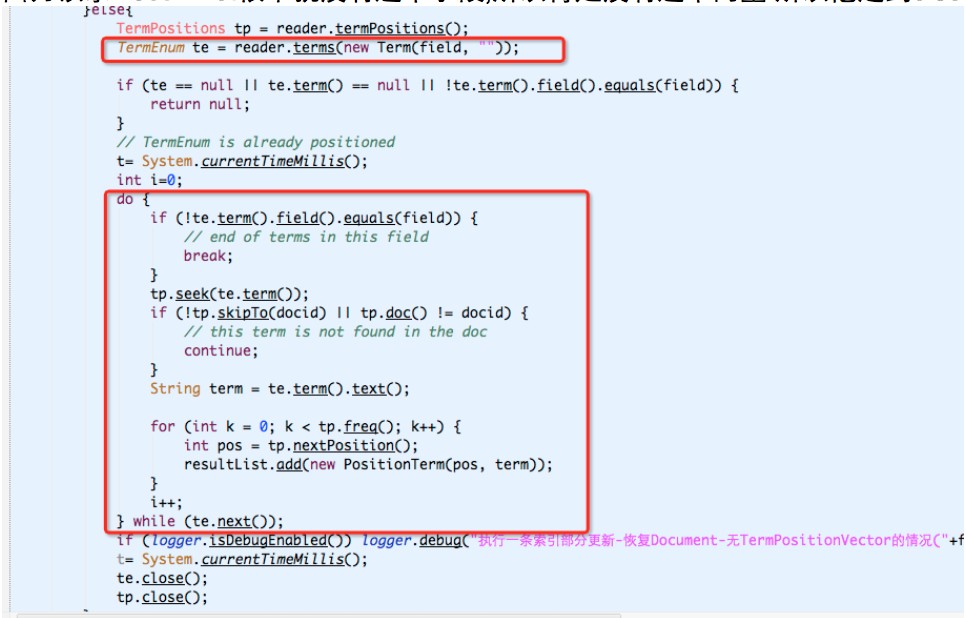
else中的处理是先读到该字段的所有term. digitalTapeBarcode大概有2万个term.然后把这些term都取出来.遍历所有的term.然后判断这个term是否是属于这个document的.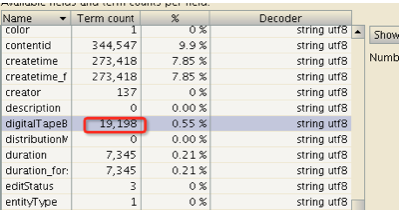
程序的结果也符合预期:
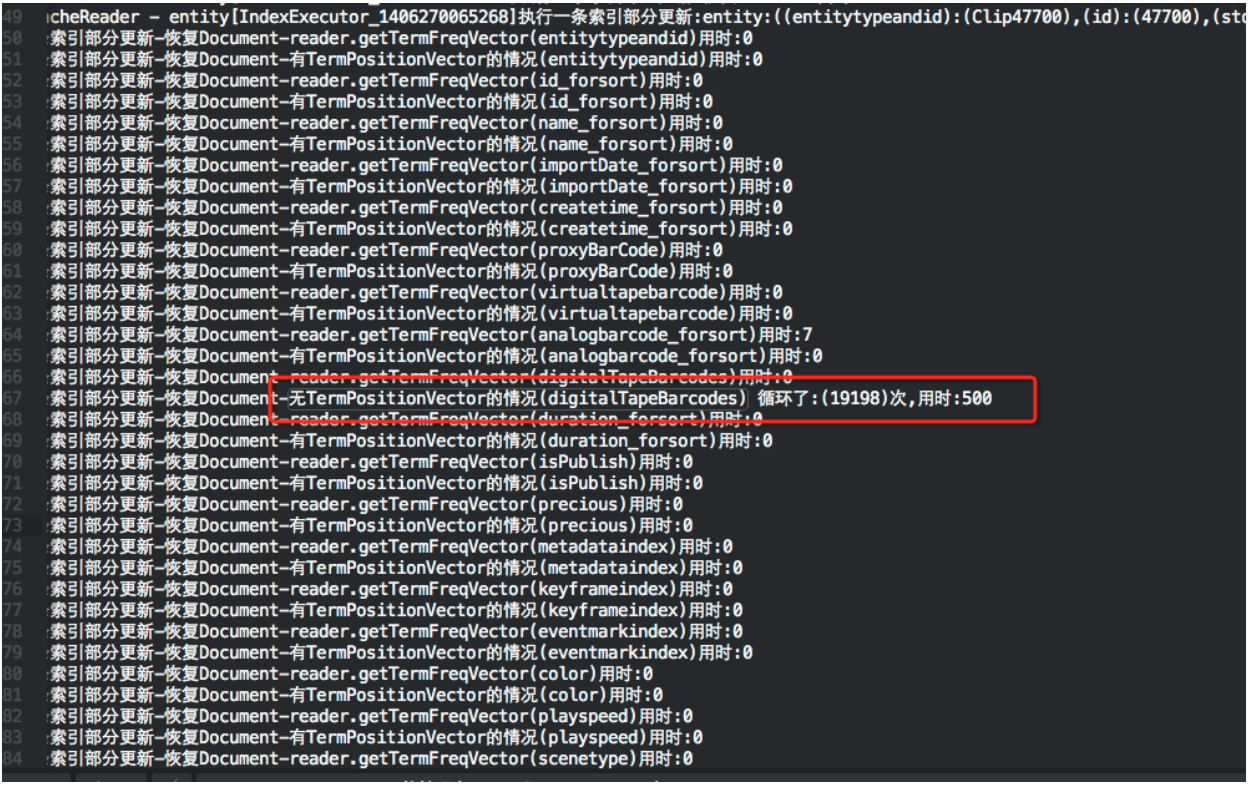
找到问题原因后,就着手进行修改. 由于Lucene本身没有提供根据document来查询这条记录是否有这个字段.所以我们才会进行遍历.这也是无法修改的.
但是,在这我使用了一个取巧的办法.
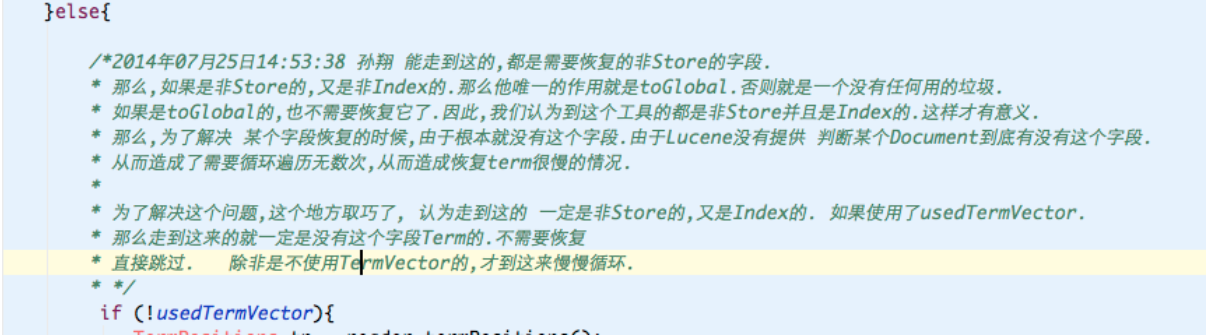
也就是认为如果在使用TermVector的情况下(现在的索引,在北京台之后的都是使用了TermVector的).
如果在TermVector中没有找到,就认为该Document中没有这个字段,不需要恢复.也就没必要去遍历这几万次.

相同的90条记录,进行部分更新. 修改前用时 38778毫秒 ,修改后 4475毫秒. 基本认为问题解决.
在不修改底层到Lucene的情况下,只能这样了
- 做1W条记录的批量部分更新测试:
修改前: 开始时间: 2014-07-25 11:57:35,666 结束时间:2014-07-25 13:12:39,811 共用时:4504秒
修改后:开始时间:2014-07-25 17:20:23,382 结束时间:2014-07-25 17:25:57,946 共用时:334秒
- 到此,问题基本解决

