
记一次JVM优化过程
问题的引出
在多个系统环境中都出现了我们的DCMP在运行过程中突然停止响应,并且时间长达几分钟至几十分钟之久.期间DCMP任何功能都无法运行.严重的影响了系统的运行.因此需要分析排查问题的原因
解决思路
经过最初步的分析,发现是DCMP在运行一段时间后,会执行FullGC. 在FullGC的过程中整个系统会停止一切响应.因此,解决该问题的思路,就是分析出DCMP平凡进行FullGC的原因.然后进行优化
分析过程
在DCMP运行的过程中,通过windows任务管理器找到进程的
PID.然后调用JDK自带的命令:1$ jstat –gcutil PID 重复次数 间隔时间获取当前JVM的内存信息:
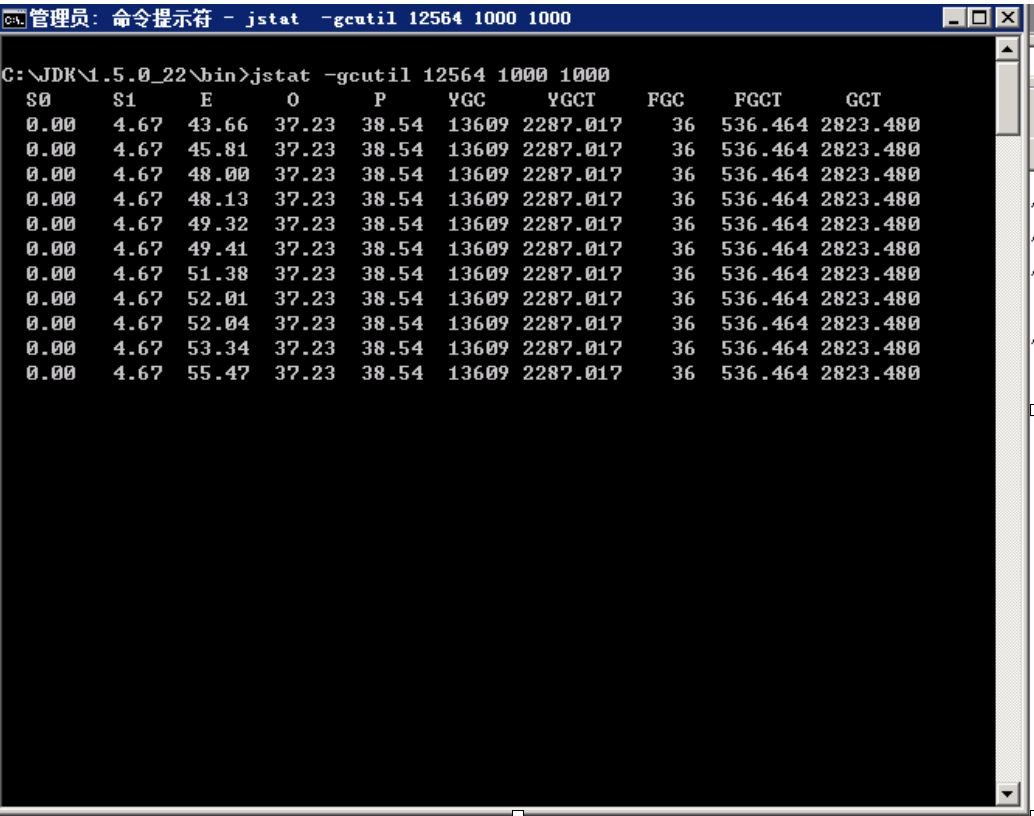
他上面标识了JVM中每一个区的说占用百分比.
通过一段时间的观察,发现DCMP每一次
FullGC都是由于Perm区内存空间占满造成的,而不是Old区. 在JVM定义中Perm区是持久区.用于存放ClassLoader和Class的类信息以及常量的.理论上是不会大量的增长的.因此在分段式的GC中是不会被GC的.只有在FullGC中会被GC.而我们的系统中,1G的perm区,仅仅需要10分钟就会被填满.这肯定是有问题的.经过系统最小化的测试原则.也就是把能去掉的模块都去掉,仅仅保留DCMP运行的最少模块.发现
Perm区的增长和CDPLB(我们系统中的一个组件与任务调度的服务)的轮询时间高度一直.有理由相信和CDPLB有关.于是排查代码.发现对于一个CDPLB的任务,他在每一次轮询的时候都要调用ITaskRedirector的实现类进行分析获取该任务需要交由哪个执行器来处理.于是修改CDPLB的逻辑,让每一个任务在添加的时候就调用一次ITaskRedirector去获取执行器的名字.上线后,再次调用jstat命令发现perm区的增长后明显的好转.但是对于一般的情况,增速还是过快.特别是进行保存元数据的时候,会进行明显的增长.再次分析
ITaskRedirector实现类与保存元数据的逻辑的共性.发现都有xml转换对象的步骤.初步猜测与这个有关.于是编写测试类:

该断代码的逻辑在于读取一个临时实体的XML字符串. 然后不断的循环,一次采用XStream来反序列化生成临时实体对象,一次采用Dom4j来生成临时实体对象.两种方式交替执行.每次执行停顿5000毫秒.该代码执行后,通过jstat分析得出,每当使用XStream生成临时实体的时候Perm区都会增长0.5%左右.而使用Dom4j不会(如果使用Dom4j的XPATH功能,会增长0.1左右).由此可以断定应该是Xstream在反序列化XML生成对象的过程中产生了动态的代理Class.造成了perm区的增加.根据网上查到的说法,
Xstream是线程安全的,因此修改代码.把以前每调用一次序列化/反序列化 就要注册一次Xstream改为了缓存常量.经过这次修改,Perm区增长的问题基本解决.每一次的FullGC都不是由于Perm区满了引起的了.继续使用
jstat分析,发现系统虽然FullGC的频率降低了,但是每一次FullGC的持续时间还是很久.经过进一步的查资料,我们现在使用的是Parallel GC,也就是并行GC.该GC的特点是并行处理Minor GC.系统吞吐量优先,也就是说,它会尽量减少GC的次数,等到内存满后再进行一次FullGC.所以FullGC的时间相当的长.因此,更换GC方式为CMS GC.CMS GC全称Concurrent Mark-Sweep GC.它是一种并行的标记GC.当有部分内存需要被GC的时候,它会标记这部分内存.然后系统就不再使用这部分内存.同一时间,它开始并行的开始释放被标记的这部分内存.从而达到高响应的.它是一种高响应式的GC,它为了能减少GC的时间,通过不断的标记和交换内存来达到目的.因此对于系统的吞吐量是有一定的影响的.决定选用CMS GC方式后,还需要决定的就是整个系统的堆大小以及每一个区的大小.
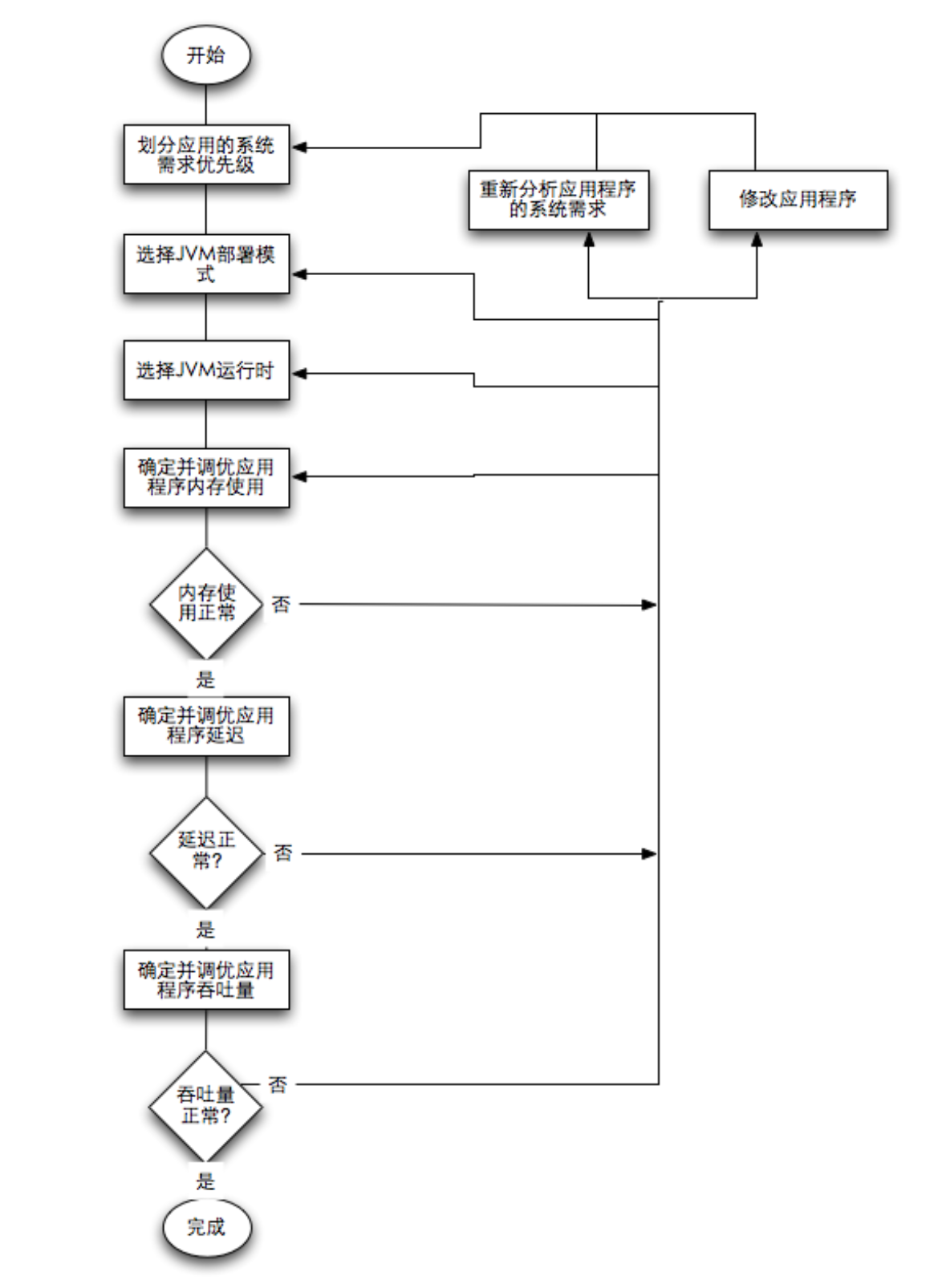
判断JVM是否调优有三个标准:吞吐量,延迟及响应性,内存占用.
吞吐量是对单位时间内处理工作量的度量,设计吞吐量需求时,一般不考虑它对延迟或响应时间的影响.通常情况下,增加吞吐量的代价是延迟的增加或内存使用的增加.吞吐量性能的需求的一个典型例子是:应用程序每秒需要完成2500次事务.延迟及响应性是对引用程序收到指令开始工作直到完成该工作所消耗时间的度量.通常情况下,提高响应性的代价是更低的吞吐量,或者更多的内存消耗.延迟需求的一个典型例子是应用程序应该在60ms内完成请求的处理工作内存占用是指在同等程度的吞吐量,延迟,可用性等前提下,运行应用程序所需要的内存大小.内存占用通常以运行应用程序需要的JAVA堆大小或运行应用程序所需要的总大小来表述.一般情况下可以通过增大JAVA堆的方式增加内存能够提高吞吐量,降低延迟.
我们的DCMP系统目前暂时没有一个硬性的吞吐量或响应的要求,但是要求尽量在等量内存下达到最大吞吐量或最低响应时间.要达到这个要求有三个原则:
- 每一次MinorGC都尽可能多的收集垃圾对象.遵守这一原则可以减少应用程序发生FullGC的频率.FullGC的持续时间总是最长的.是应用程序无法达到其延迟或吞吐量要求的罪魁祸首.
- 处理吞吐量和延迟问题时,垃圾处理器能使用的内存越大,即JAVA堆空间越大,垃圾收集效果越好.
- 在这三个性能指标(吞吐量,延迟,内存占用)中任意选择两个进行JVM调优.
开始优化内存之前,需要理解JVM中堆的布局非常重要,它直接可以从理论上帮助我们确定应用程序使用JAVA堆的大小,微调影响垃圾收集器性能的空间大小.

JVM主要有三个空间,分别是:新生代,老年代以及永久区.
JAVA应用程序分类JAVA对象的时候,首先在新生代空间(Eden)中分配对象.经过一次MinorGC后,存活下来的对象会放入S0区.然后S0和S1交换.当再一次MinorGC后,把存活下来的对象再放入当前的S0区.经过几次MinorGC之后还保持活跃的对象会被晋升到老年代中.永久代中空间存放的是VM和JAVA类的元数据已经驻留的Strings和类静态变量.- 整个JVM堆大小可以使用
–Xmx和-Xms指定 - 新生代可以使用
-XX:NewSize-XX:MaxNewSize或者–Xmn指定 - 老年代空间大小会根据新生代的大小隐式的指定.即 老年代=堆大小-新生代
- 持久代空间大小通过:
-XX:PermSize-XX:MaxPerSize来指定
新生代,老年代,永久代这三个空间中的任何一个不能满足内存分配请求时,就会发生垃圾回收,理解这一点非常重要.
- 整个JVM堆大小可以使用
有了理论的知识后,接下来就是根据我们系统具体的进行分析了.首选需要的就是选择JVM运行模式.毫无疑问,我们系统肯定是使用的
Server模式.Server模式提供了更复杂的生成码优化功能,这个功能对于服务器的应用而言尤其重要接下来就是确定内存占用.程序的内存并不是越多越好,这需要考虑成本等问题.初始堆大小通常应该是老年代活跃数据的3-4倍.永久代大小应该比永久代活跃数据大1.5-2倍.新生代大小通常应该是老年代活跃数据的1-1.5倍.
所谓的活跃数据,即应用程序运行于稳定态时,长期存活的对象在JAVA堆中占用的空间大小.换句话说,活跃数据大小是引用程序运行于稳定后,FullGC之后JAVA堆中老年代和永久代占用的空间大小.
经过在107机器上大规模的跑hotfolder入库(文件分析-保存元数据).我们老年代的活跃数据大概为1个G.因此调整初始化堆大小为4G,永久代346m,新生代1.5G
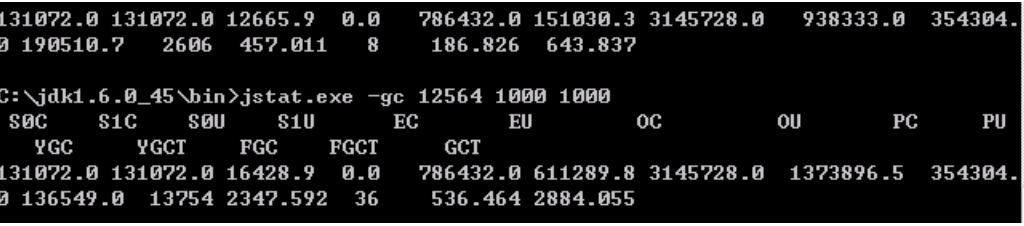
接下来微调新生代的大小.
通常情况下,新生代空间越小,MinorGC持续时间越短,不考虑这对于MinorGC持续时间的影响,减少新生代空间又会增加MinorGC的频率.因此需要取它们的中间点.分析GC数据的时候,如果发现MinorGC的间隔时间过长,修正的方法是减少新生代空间.如果Minor频率太高,修正的方法是增加新生代空间.经过GC日志的分析,新生代1.5G的空间比较合适我们的系统,每次MinorGC的平均时间为0.04秒左右.
微调老年代的大小.
这一步的目标是评估FullGC引入的最差停滞时间以及FullGC的频率.
同年轻代一样,老年代的优化也需要采集垃圾手机的统计数据.我们关注的是FullGC的持续时间和频率.经过采样,发现了一个问题.在当前的配置情况下,当系统运行了一段时间后,会进行大量的FullGC.而不进行MinorGC. FullGC占到了所有GC的90%以上.虽然每一次FullGC的持续时间都不长,但这是不正常的,经过GC日志的分析.发现,当系统进行大量的FullGC的时候,老年区与持久区并没有被占满,也就是说FullGC不是这两个区被占满造成的.每次出发FullGC的时机都是年轻代占满,进行GC的时候.报concurrent mode failure
经过oracle等论坛的查询和源码的分析,发现出现这种现象有一种情况就是当年轻代GC的时候,他需要向老年代晋升对象,而老年代的空间如果不够年轻代晋升的对象时(这里有一个误区,也是让我疑惑了很久的地方,就是明明老年代的空间大于年轻代,为什么还会不够.原因在于CMS方式的GC是不会整理内存的,内存空间是一个一个的片段.当老年区的最大连续内存片段小于年轻代晋升的对象大小时,JVM就会认为空间不足),就会发生MinorGC失败,从而JVM尝试进行FullGC.因此,可以得出一个结论就是年轻代和老年代空间大小比过小了.在不增加堆空间大小的情况下,就只能减少年轻代的空间.因此,重新修改年轻代大小为1G.Survivor空间调优
Survivor空间也就是图上的S0S1空间. 两个空间的大小虽然很小,但是作用很大.整个Survivor空间分成了两个部分,即S0和S1,也叫From区和To区.它相当于是一个缓存区,能提高年轻代晋升到老年代的对象的命中率.一旦完成MinorGC,Eden空间会被清空,From空间也会被清空.而To空间中保留了还是活跃的对象,之后Survivor空间交换标记为下一次MinorGC作准备.现在被清空的From区被标记成了To区,而To区被标记成From区.因此MinorGC结束时,Eden空间和一块Survivor空间被清空,另一块Survivor空间中保留经历了上一次MinorGC存货下来的活跃对象.如果MinorGC时.To区空间不足以容纳所有从Eden区和From区中复制过来的活跃对象,超出的部分就会直接晋升至老年区.这会加速FullGC的频率.调整Survivor空间的大小,让其有足够的空间容纳存活对象足够长的时间,直到几个周期之后对象老化.就能避免Survivor空间的溢出.
调整Survivor空间大小可以通过:-XX:SurvivorRation=<ratio>进行调整.
计算公式为:Survivor空间大小=-Xmn/(+XX:SurvivorRation=<ration>+2)
要调优Survivor空间,需要监控晋升阀值.晋升阀值决定了对象在新生代Survivor空间中保留的次数.通过在GC日志中增加-XX:+PrintTenuringDistribution.来监控晋升阀值.
增加该参数后,每一个MinorGC都会打印Survivor区中的对象大小以及保留次数:
比如:age 1: 6115072bytes, 6115072 total
age 2: 286672bytes, 6401774 total
age 3: 115704 bytes, 6517448 total
age 4: 95932 bytes, 6613380 total
age 5: 89465 bytes, 6702845 total
age 6: 88322 bytes, 6791167 total
age 7 88201bytes, 6879368 total从上表来看,年龄为
123的对象非常的多,而年龄4开始就很少了.也就是说系统的Survivor的晋升阀值就是3.即-XX:MaxTenuringThreshold=3.整个年龄为3的对象为65兆.所以就配置Survivor区大小为130m.即-XX:SurvivorRatio=6CMS收集周期调优
确定完JVM堆以及每一个区的大小后,还需要的就是根据CMS收集策略来调整一些参数.比如:- Perm区满后是采用FullGC还是直接抛异常终止系统运行的
-XX:+CMSPermGenSweepingEnabled参数. - CMS老年代开始标记的进入周期,如果CMS周期开的太晚,就会发生失速.如果它无法以足够快的速度回收对象,就无法避免老年化空间用尽.但是如果CMS周期开始得过早,又会引起无用的消耗,影响应用程序的吞吐量.经过GC日志的分析,当老年代占用大于1.6G的时候,就会发生concurrent mode failure.因此决定CMS进入时机为老年代的60%,即:
-XX:CMSInitiatingOccupancyFraction=60 - CMS回收不会整理内存,这就会造成老年区的内存碎片越来越多,影响效率.因此就需要指定进行几次FullGC后,整理老年区的内存.这会增加一个FullGC的时间,但是可以整体的增加系统的吞吐量.经过分析我们的系统很久才会触发一次FullGC,于是配置每一个FullGC前都进行内存整理:
-XX:CMSFullGCsBeforeCompaction=1
- Perm区满后是采用FullGC还是直接抛异常终止系统运行的
到此,GC的配置已完成,然后就是进行大量的测试.现在的配置如下:
|
|
经过3台AT导入同时导入的压力测试: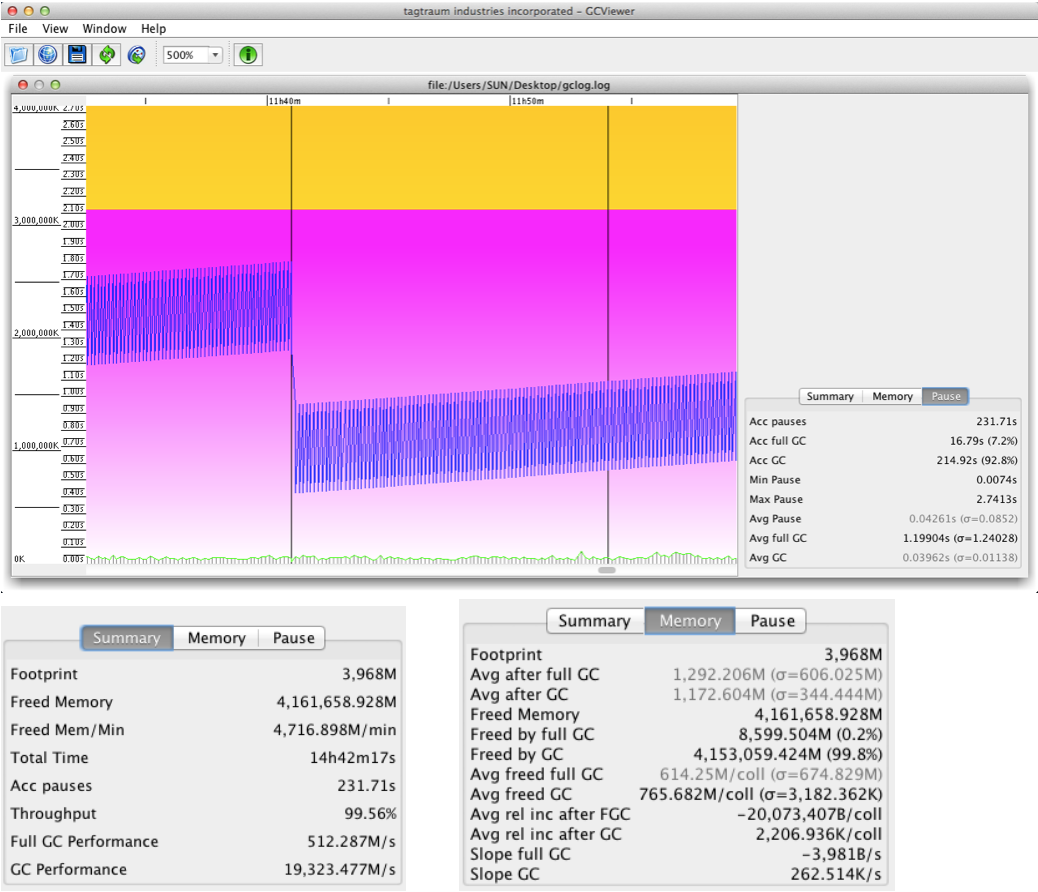
系统运行52937秒,整个GC暂停时间231.71秒. 系统可用时间 99.56%.平均GC时间0.039秒,最大停顿时间2.7秒.达到系统要求.
把同样的配置发到旺旺现场,发现系统还是响应很慢,收集GC日志后发现.他们的元数据太大.造成新生代被占满的速度太快.平凡的进行MinorGC. 平均每0.2秒就进行一个MinorGC,系统停顿0.04秒. 整个系统的可用时间只有75%.没达到吞吐量的需求.日志显示0.2秒新生代的900M空间就会被占满.但是不会平凡的进行FullGC.证明整体的GC策略是正确的,但是确实由于量的原因,4G空间不能满足要求了.所以一方面增加现场的内存配置到8G.另一方面,分析流程,发现由于AT导入速度大于我们保存元数据的速度.所以保存元数据的流程越来越多,而保存元数据没有使用CDPLB调度,所有的任务都驻留在内存中,造成了新生代增速过快.因此,修改程序让CDPLB也来调度保存元数据,同一时间只有300个任务驻留在内存中.再次观察日志.问题解决.
至此,整个DCMP的内存调优结束.

